Going paperless
A paperless existence is something I’ve long dreamed about.
I am not a person often described as ‘organised’. I hate paperwork, I hate filing, and consequently I hate the piles of paper that clutter up my life. I bought the first-generation Doxie (a little document scanner) intending to rid of the administrative detritus in my life. That was about two years ago, and I’d never really managed to get the whole paperless thing going. I’d scan some things, not scan others, and so in the end my small collection of scanned documents was almost completely useless. And my occasional attempts at establishing a proper process for dealing with my documents had fizzled.
Until this weekend that is. On no-work-Friday I read Shawn Blanc’s post “The Paperless Puzzle” and (as it did for Shawn) everything clicked into place for me. All it took was an easy way to OCR my scans, and the wonderful Hazel (and to a lesser extent Dropbox).
OCR
If you have the newer version of the Doxie (the Doxie Go) then you’re already set on the OCR front: out of the box it will OCR your documents as you scan them. Alas, my first-gen Doxie doesn’t have that feature, so I had to find another option. As luck would have it, I already use the excellent PDFpen for any PDF editing needs I have, and it has simple and fast OCR support built in. All you need to do is choose “Edit > OCR Page” and you’re away.
Hazel
Hazel is where all the magic begins. It’s a little Preference Pane for OS X that’s billed as “Your Personal Housekeeper”. Basically, it keeps watch over folders on your computer and then lets you set up rules to act upon the files in those folders in different ways. This makes it the perfect tool to automate some of the pointless busy-work that comes with dealing with going paperless.
Opening, OCR-ing, and saving every scanned document is exactly the sort of tedious work that makes my attempts at administration fall apart, so the first rule I added with Hazel automates that process:
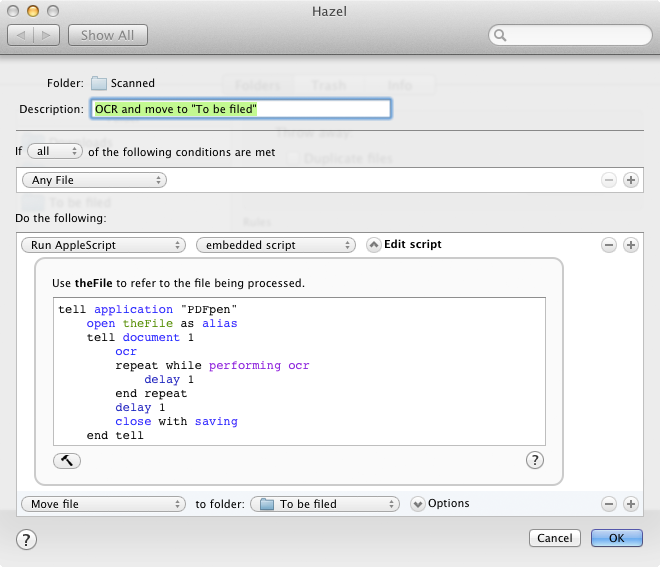
This instruction takes anything added to my “To be scanned” folder and runs an AppleScript that tells PDFpen to open the new file, perform OCR on it, and then save it. Once that’s complete, there’s a second action in the rule that moves the newly OCR-ed file to my “To be filed” folder.
My next set of rules is almost exactly as Shawn describes it in his post. Hazel can read the contents of PDF documents, which means you can create rules that handle your files in different ways depending on their contents. This is why the OCR-ing is important; without it Hazel cannot read the contents of your files. For each of the different types of documents I have — bank statements, phone bills, insurance bills, gas bills, electricity bills, etc bills — I create a rule that matches a unique set of text in the document and then renames the file to something useful and moves it to the appropriate place in my filing folders.
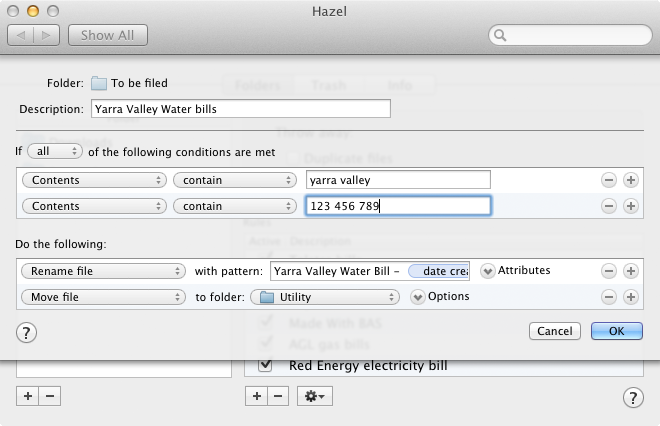
Here I’m check the document contains the name of the service provider (“yarra valley”) and my account number (“123 456 789”). If both those conditions are true, the file gets renamed “Yarra Valley Water Bill — YYYY-MM-DD.PDF” and moved to the “Utility” folder. While it takes a little bit of work get things set up — I have about ten of these rules so far — once up and running the process filling away new documents takes only the time spent scanning and saving them to the “To be scanned” folder. And best of all, I no longer have to think about how my filing system is supposed to work. I can scan, save, and forget.
The other great thing about this setup is it works for all the bills I get electronically as well. As long as I can get a PDF of the bill somehow (and on OS X that’s usually as easy as “Print > Save as PDF”) then the Hazel rules will eventually take care of it.
Since my folders are all sitting in Dropbox, I can also take advantage of this setup when I’m out and about. There are a whole bunch of iPhone scanning apps out there, I happen to use TurboScan which, despite its horrible interface, is perfect for this situation. Its lets you stitch together multiple photographs and save them as a single PDF in Dropbox. To deal with these ad-hoc documents, I use a name-based rule for the common types:
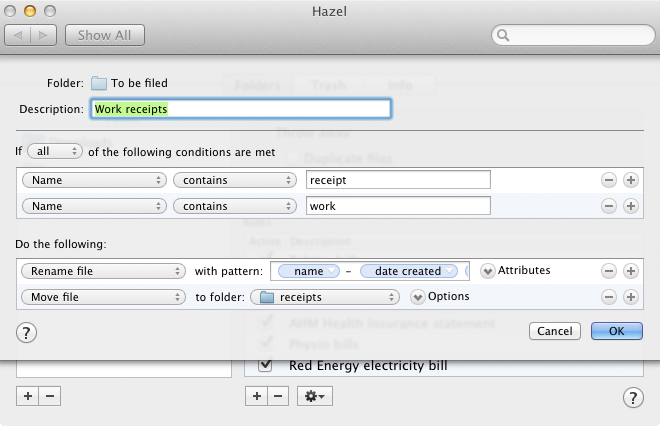
So now if I want to keep a receipt while I’m away from my computer, I can add them to my “To be scanned” folder through Dropbox on my iPhone with a name like “Boozy lunch work receipt” and, when I open my laptop, they get automatically OCR-ed and sent off to the right place.
Magic.